
Machine Learning within Location Planning
Machine Learning is not new. We have used it in Location Planning for years, but new advancements mean now we can do more. Danny shares more about the Geolytix ML journey.
3rd October 2022 • AI

Machine learning has been an ever increasingly hot topic for some time now. As CPU and GPU speeds have increased, advanced algorithms/statistical models can more quickly provide insight and answers for a range of complex problems. New libraries and techniques are constantly evolving and improving.
Machine Learning within Location Planning
When reading about AI or ML though, you’re often presented case studies from large tech companies such as Spotify’s recommendation algorithms, or Facebook’s former facial recognition neural networks. These types of models, in addition to much of the teachings on the subject, are reliant on large sample sizes.
So how have advances in machine learning affected location planning techniques, especially when we often must deal with significantly smaller datasets than this? Even a large network of 1,000 stores is relatively small compared to most case studies…
Well, whilst all of these advancements are very exciting, it’s more a case of evolution than revolution. Location planners have been using machine learning techniques for years. Even a simple linear regression model is machine learning. The computer simply calculates the coefficients/weights of each variable. Geodemographic segmentations too have been built using clustering algorithms for many years. New model libraries and faster computational speeds though, have expanded the tools available to us.
Model innovation when working with rich data samples
Where we have had rich data sources (e.g. aggregated customer spend data) we have been able to build complex granular market share forecasting models, challenging more traditional techniques. Some of our recent case studies include replacing gravity models with gradient boosted decision trees for grocery clients, or using machine learning to predict F&B delivery sales at postcode level. Thanks to cloud-based clusters we can run hundreds of iterations of these models to achieve the best calibrations, resulting in more accurate models.
Some of our model data inputs too are built using machine learning techniques. In markets with no granular population data, deep learning combined with aerial imagery enables us to disaggregate known populations according to how “built-up” an area is. Clustering algorithms are used for customer segmentation and our urbanity classifications. Using AutoML techniques have allowed us to compare the effectiveness of different algorithms for different problems. We’ve used natural language processing to classify menu items based on their names, the list goes on.
All of these approaches above may not have been as easily available to us until relatively recently, but most do require significant volumes of data. So, what about when we’re trying to solve problems with smaller sample sizes?
What about when we don’t have huge data samples?
Often in the location planning world, the reality is that we don’t have rich, geocoded customer data available to us. Often store networks may not be expansive, especially when newly entering a market. Let’s imagine we’re building a sales forecasting model to help identify new potential store locations, and we have 300 existing stores on which to train our model(s). This sounds like a healthy sample size, but in machine learning terms it’s relatively small. What’s more, this sample of 300 stores might consist of 100 shopping centres, 150 high street and 50 train station locations; all of which potentially have different sales drivers and might even require separate models. There is still a need to predict new store sales as accurately as possible, and we can use machine learning principles to help us achieve this, but we shouldn’t do so blindly.
We might auto-calibrate a machine learning model, or run correlation analysis, and find that the “most important” feature of a store is, for example, its opening date. At this point, it is vital that we challenge each of these potential inputs. A store’s opening date may be misleading as older stores must perform well enough to survive any closure programmes, it doesn’t necessarily mean that the older a store gets, the more revenue it will make. Machine learning cannot make this distinction, it’s a judgement call the data scientist must make. Another common example is when using any ‘distance’ measures as model inputs. For example, being close to a traffic builder (e.g. supermarket) may have a positive effect on sales, but is this correlation being driven by a just handful of coincidentally poor performers located very far away from a supermarket? Is the model favouring locations which are 5 metres away as opposed to 50 metres away (this is 10x further away after all)? In this case, we may need to manipulate or scale our input data. How about new store formats, or stores which are opening in locations dissimilar to the current network – will the algorithm know how to handle these?
There are many questions like these which we must ask as we stress-test our models. Ultimately, we want our models to not only produce the most accurate results, but also to make sense to the end-user. With smaller sample sizes it is especially important to take care as we build our forecasting tools to prevent overfitting, or misleading correlations and accuracy from smaller training and test sets. Thankfully at Geolytix we have many experienced location planners who work alongside the data science team to ensure that this is the case. In many cases, a model with more straight-forward logic might be more appropriate, but we can still take learnings from machine learning approaches to challenge the more traditional methods.
The Importance of Explainability and Final Notes
Explainability is another important consideration. It’s unfair to call all machine learning models “black-box”, but they often can be harder to understand than for example a traditional scorecard approach. We can still determine how important each model variable is, and python libraries such as SHAP or LIME can help us understand more about how exactly these variables interact with each other, and the final forecasts.
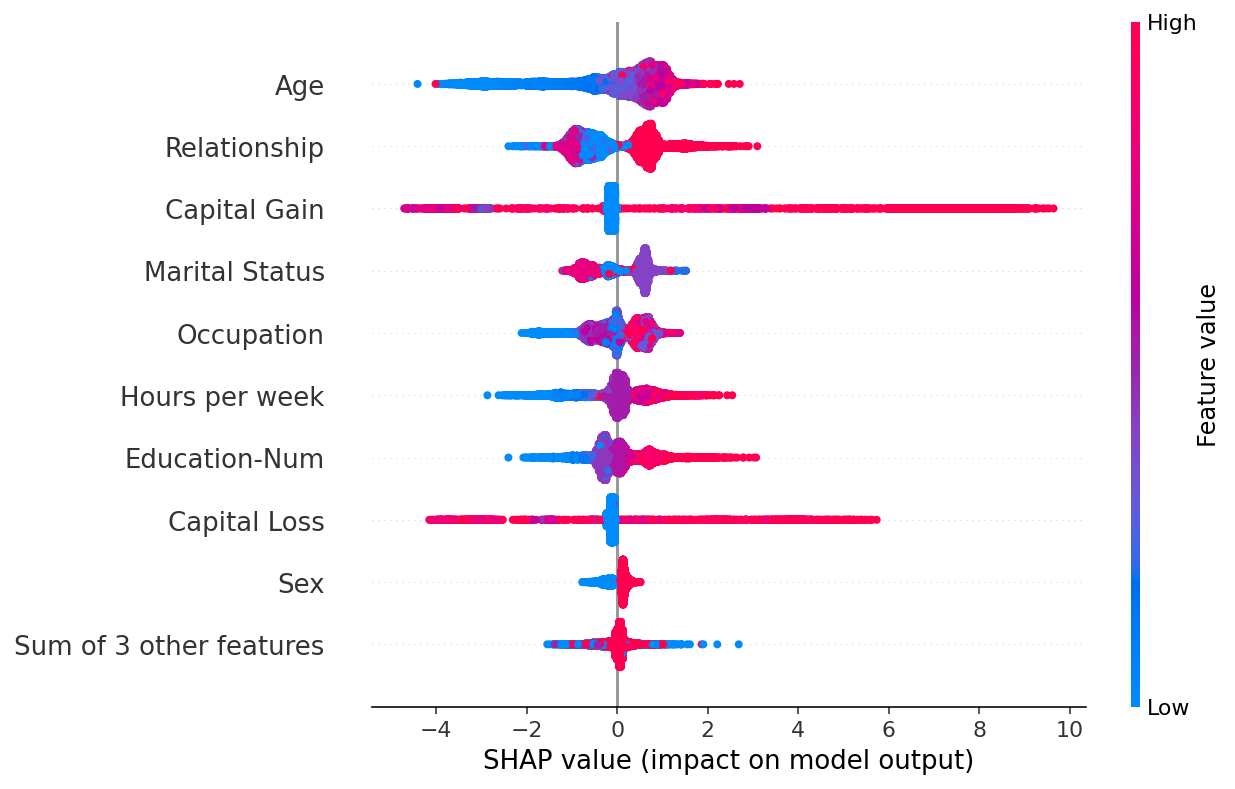
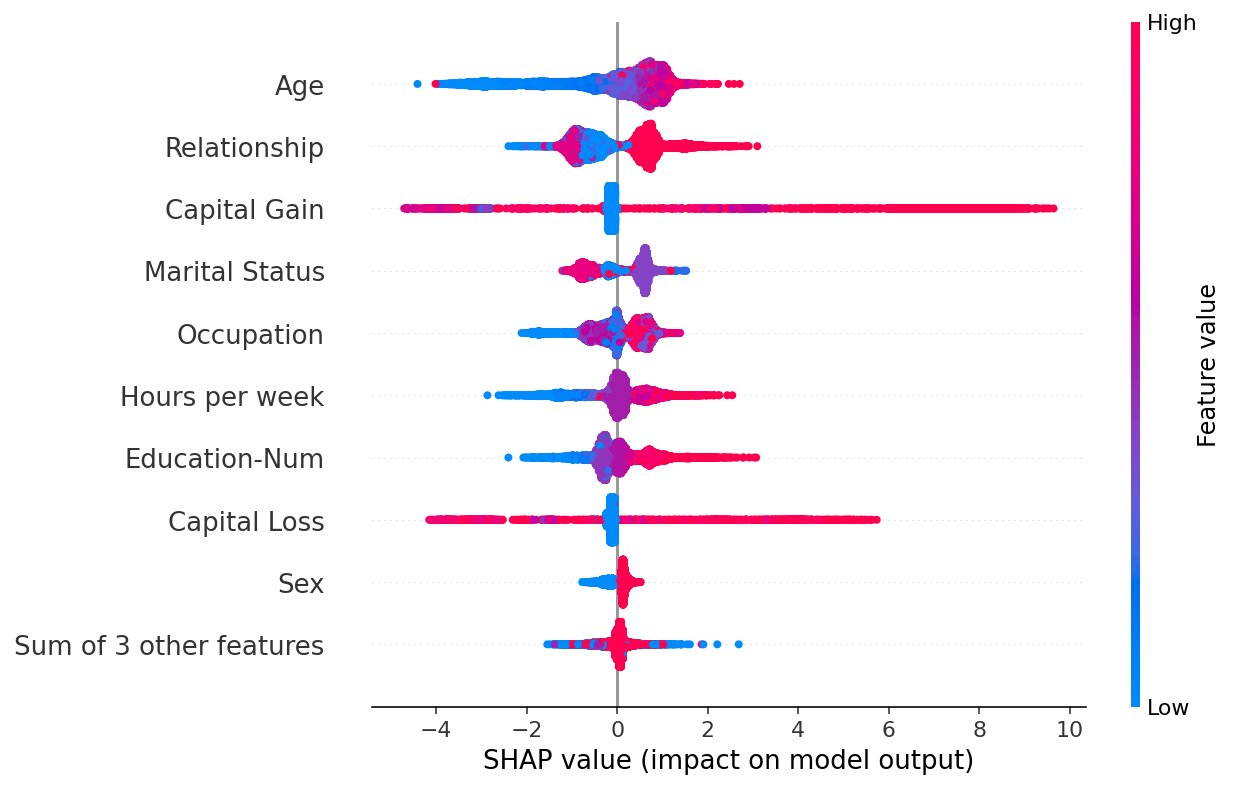{kind=link}
If the end user has been on the model building journey then this level of explainability may be more than enough, especially if the end result is a more accurate model. But what if the model forecasts and reports are shared amongst many within the business? Is a 5% improvement to accuracy worth it if stakeholders can’t easily understand how the end forecast is reached?
Ultimately there are many considerations to be made when building any models, especially in the location planning world where we’re forecasting complex consumer behaviour, often with smaller sample sizes. At Geolytix we’re model-agnostic, and work together with our clients to select the best approach for each problem. Machine learning advancements have equipped us with more tools than ever to do this, but it’s important not to forget the importance of experience and how the end results will be used.
Danny Hart, Head of Data Science at GEOLYTIX

Related Posts
-

The Geolytix Podcast: AI Series
Where location intelligence meets AI. Join Ed Parsons and the Geolytix team for a 6-part podcast cutting through the hype to find real clarity.
Published 1st July 2026 • Tags ai, team-thoughts
-

What’s the Catchment?
Catchments are more than just shapes on a map. Discover 7 ways to map your customers, analyse competitors, and optimise your location planning.
Published 26th May 2026 • Tags team-thoughts
-

HighStreetsPositive - Changing the Negative Narrative
Helping high streets thrive through data, collaboration and community. Read our five top tips with HighStreetPositives.
Published 13th March 2026 • Tags team-thoughts